Supporting high-performance response streaming in Shardcake

Shardcake is a Scala open source library I created in 2022 to easily distribute entities across multiple servers (sharding) and to interact with them using their ID without knowing their actual location (location transparency).
To support a real-life use case, I recently added the ability to stream messages from remote entities to multiple recipients. While doing so, I encountered a few issues and challenges that I am sharing here in the hope that they are helpful to others. Knowledge of zio or cats-effect is recommended (Shardcake itself is based on zio/zio-streams, but most concepts are the same in cats-effect/fs2).
Basics
Let’s look at a very simplified example first. To communicate with remote entities, we send them messages, which are typically defined in an enum.
enum UserMessage {
case Greet(message: String, replier: Replier[String])
}Our User entity will be able to handle messages of type UserMessage. There is only one subtype: Greet. It contains a Replier[String], which means that the entity can reply to the message sender with a String by simply calling replier.reply.
class User {
def handle(protocol: UserMessage) =
protocol match {
case UserMessage.Greet(message, replier) =>
replier.reply(s"Received $message")
}
}On the sender side, we need a Messenger[UserMessage], and we can use its send function to send a message to any User entity and get back a String.
class Service(user: Messenger[UserMessage]) {
def greetUser(userId: String, message: String): Task[String] =
user.send(userId)(UserMessage.Greet(message, _))
}The default implementation of the transport layer uses gRPC to communicate between the sender and the remote entity, but it is possible to plug in a different protocol instead.
The problem
I’ve been using Shardcake at work for a couple of years already, and our workflows usually look like this:
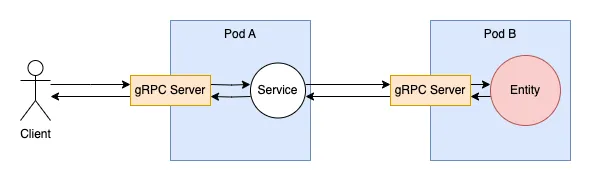
Client requests hit a first pod’s gRPC server, then each request is dispatched to a service that eventually calls the send method we just saw. That triggers a call to another pod (unless we’re lucky and the entity is hosted by the same pod), also using gRPC. The second pod’s gRPC server forwards the message to the local entity, and the entity’s reply is sent back as a response to the gRPC call. The service can then process this response and return a response to the client.
However, we had to develop a new feature where multiple users would be part of a “channel”, and any action from one user should be forwarded to all users in the same channel in real time.
That meant that the workflow wouldn’t be that simple anymore. Upon receiving a message, the entity would have to dispatch the reply back to multiple clients instead of one.
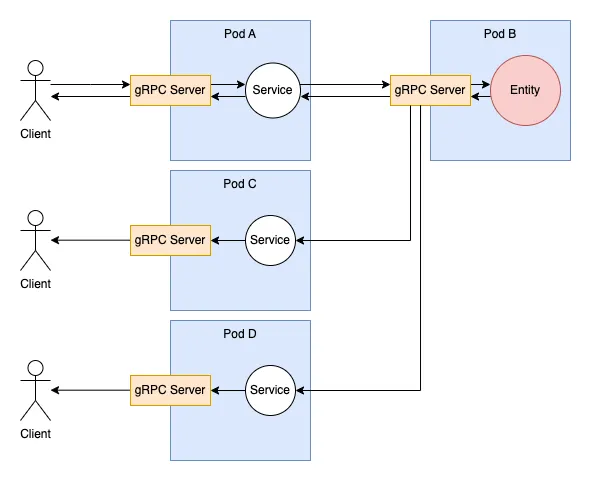
Initial support
The implementation of send took two parameters: an entity ID (to locate our entity in one of the pods) as well as a function providing a Replier[Res] to construct a Msg (Msg being the message protocol of the entity). This function returns a Task[Res].
def send[Res](entityId: String)(
msg: Replier[Res] => Msg
): Task[Res]
case class Replier[-R] {
def reply(reply: R) = ???
}I created a similar API for being able to reply not with a single response but with a stream of responses. sendStream returns a Stream of Res, and the entity should now call replyStream with a Stream of Res instead of a single Res.
def sendStream[Res](entityId: String)(
msg: StreamReplier[Res] => Msg
): Task[Stream[Throwable, Res]]
case class StreamReplier[-R] {
def replyStream(replies: Stream[Nothing, R]) = ???
}There were 2 major differences in the implementation compared to the initial send:
-
I was mostly using
Promiseto handle replies from entities internally, but that didn’t work with multiple replies. I had to useQueueto support multiple replies, but I didn’t want to slow down the one-reply use case, so I ended up creating an abstraction calledReplyChannelthat can wrap either aPromiseor aQueuedepending on the situation. -
Instead of unary gRPC calls for internal communication between pods, I had to use gRPC streams.
// unary case rpc Send (SendRequest) returns (SendResponse) {} // streaming case rpc SendStream (SendRequest) returns (stream SendResponse) {}
Chunking Express
Once the implementation of sendStream was finished, I could finally put together a proof-of-concept for our multi-user channel use case and start measuring the performance. And it was… slow, very slow.
I had a look at the profiler, and what I observed was that most of the CPU time was not spent in my code or even in Shardcake’s code but in ZIO and ZStream internals. Seeing too much time in ZIO’s runtime usually indicates that you are running too many IO loops.
In our test case, each client was sending multiple messages per second, and each message was broadcasted to all other clients, so we ended up broadcasting a huge number of messages.
When working with streams and dealing with a lot of messages, it’s important to consider chunking. Libraries like zio-streams and fs2 internally group elements into chunks to speed up internal processing. Both these libraries are pull-based, which means streams pull elements from upstream when they are ready to be consumed. This pulling mechanism has a cost, and doing it one element at a time is often quite inefficient when dealing with large streams of data. For example, ZStream.fromInputStream pulls chunks of size 4096 from their source by default, while Files.readAll in fs2 takes chunks of size 64KB.
Those chunks are internal though, you don’t see them in the signature of your streams unless you explicitly surface them by transforming your Stream[A] to Stream[Chunk[A]]. Most Stream constructors are smart enough that they apply some chunking by default. In our Shardcake case, my streams came from Queue, and the default ZStream.fromQueue also pulls chunks of size up to 4096 from the queue.
Why should we care about it?
The problem with the fact that these chunks are internal is that there are some operators that don’t operate on chunks but on individual elements, or worse, operators that destroy the chunking.
If you call map on your stream, internally it will call map on each chunk, which is very fast because it is a pure operation. However, if you call mapZIO or tap, you are going to run a ZIO effect for each individual element, which is potentially going to slow down your stream processing a lot. Prefer mapChunksZIO, for example, if you are able to run a single ZIO for the whole Chunk instead. Similarly, runForeachChunk will be faster than runForeach if you are able to process a chunk at once.
In Shardcake, there were a few cases where I was using individual processing:
-
.mapZIO(serialization.encode)was used for serializing messages, which is a very fast operation. I changed it to.mapChunksZIO(serialization.encodeChunk)to serialize a whole chunk of messages at once in a singleZIOand reduce the unnecessary overhead of the IO loop. The same thing applies to deserialization. -
I also had a case where I was doing
stream.runForeach(a => queue.offer(Take.single(a))), which involves consuming a stream and enqueuing every element into a queue ofTake. There is a much better way of doing this sinceTake.chunkexists:stream.runForeachChunk(c => queue.offer(Take.chunk(c)))will process whole chunks at once. There’s even astream.runIntoQueuethat essentially does that. -
A tricky case is
ZStream#buffer, which destroys the chunking. I was not using it directly, but it was being used in zio-grpc to apply back-pressure on streams and avoid running out of memory in Netty. I added the ability to avoid this call tobuffer, which was better for my use case of sending a lot of small messages.
I also added extra buffering inside my channels: instead of trying to forward messages to other clients immediately, I put them in a Queue and took all elements from the Queue every n milliseconds to send them to all clients. That way, I increased the chance of having actual chunks with multiple messages rather than many chunks of size 1.
Mysterious back pressure
Once all these changes were applied, we were able to support a much higher throughput and started testing with hundreds of channels and thousands of users.
We quickly found that we were reaching a limit: at some rate of messages, we couldn’t get any faster even though the CPU was not at 100%. We tried adding more pods: no improvements. We tried giving more CPU to existing pods: no improvements. Our worst nightmare was happening: the system was not scalable.
After a lot of digging, debugging, and logging in the application, we were able to find the culprit: it was not the internal communication but the communication with clients that was slowing us down. Netty was applying back-pressure because it couldn’t send messages fast enough. The answer finally came from our DevOps: our Istio Ingress Gateway was at 100% CPU during each of the tests and couldn’t handle all the messages. In other words, the traffic between the client and the server was being throttled.
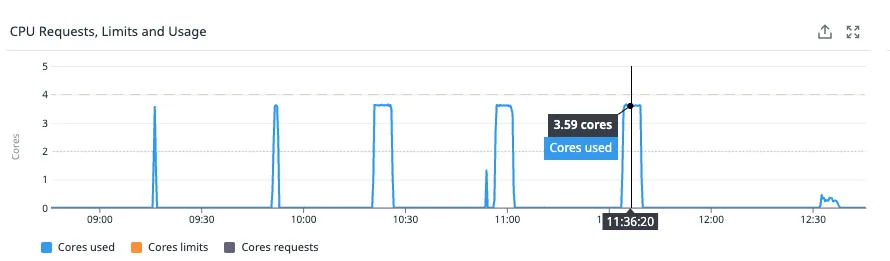
We lifted that immediately and, to our relief, were able to process a lot more messages. That was a good lesson for us: when nothing makes sense anymore, look for external factors!
Thread contention
At that point, we noticed a warning in Datadog’s live profiler:
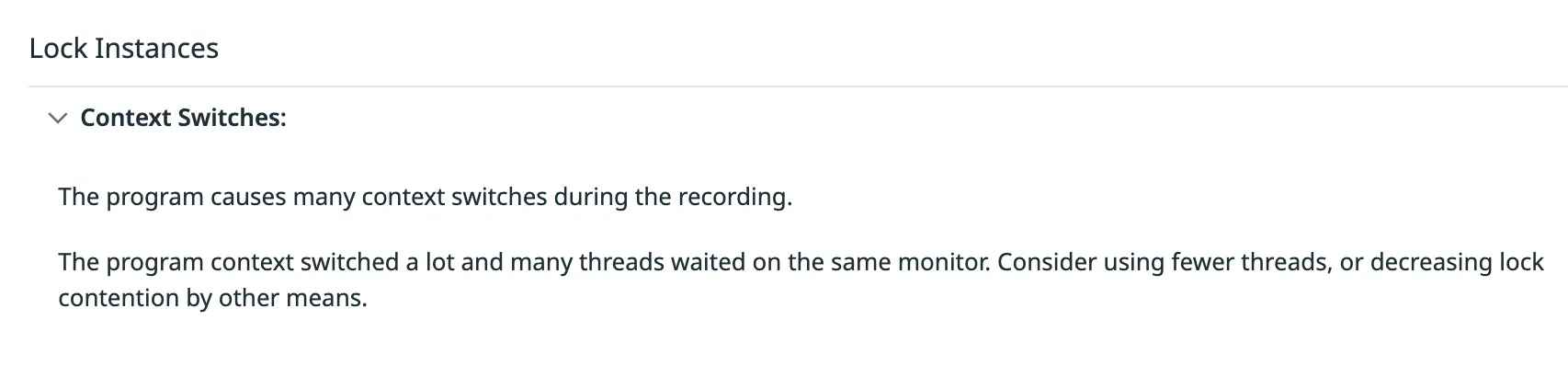
We took a closer look at threads and found that there were a LOT of threads created by the grpc-java executor (grpc-java is used by zio-grpc under the hood).
These threads were not even that busy, but it kept creating new ones. A small research led us to the following SO message:
By default, gRPC uses a cached thread pool so that it is very easy to get started. However, it is strongly recommended you provide your own executor. The reason is that the default thread pool behaves badly under load, creating new threads when the rest are busy.
In fact, it turns out the official docs recommend that you “provide a custom executor that limits the number of threads, based on your workload (cached (default), fixed, fork join, etc.)”. There is a long GitHub issue about whether the defaults should be changed or not, but they haven’t because using a fixed-size thread pool can lead to deadlocks if you are blocking in those threads. We’re using ZIO, so we should be safe, right?
We proceeded to change the executor (which required exposing the setting in Shardcake) to ForkJoinPool, and performance got even better, with now a very reasonable amount of threads. However, when our load test was about to end, all servers suddenly became unresponsive and were eventually killed by Kubernetes. Even the health check endpoint was not responding.
Fortunately, the Datadog profiler was able to capture one last profile before the servers were killed. It showed that all threads from our grpc executor threadpool were waiting on the same lock.
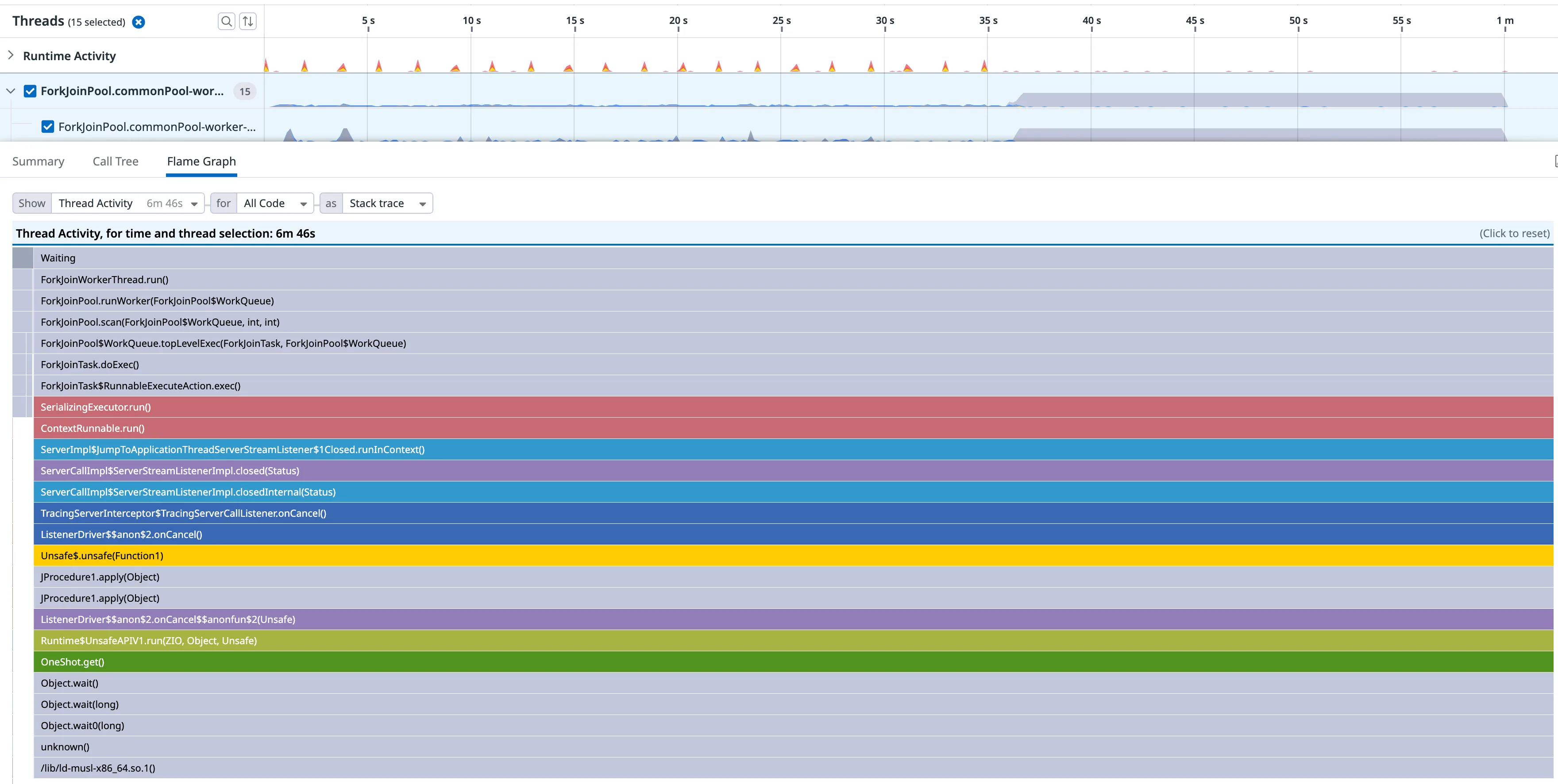
When a stream is disconnected on the client side, grpc-java calls an onCancel callback to let us know about it. In zio-grpc, this onCancel triggers the interruption of the fiber running the stream by calling fiber.interrupt.
override def onCancel(): Unit =
Unsafe.unsafe { implicit u =>
runtime.unsafe.run(fiber.interrupt.unit).getOrThrowFiberFailure()
}There is a catch, though: in ZIO, fiber.interrupt does not return immediately; it returns once the fiber is interrupted. This means that we are blocking the current thread until the interruption is done. The interruption is processed by the ZIO scheduler threadpool, so that should not be a problem.
However, looking at the creation of the fiber (the code has been simplified a bit):
stream.onExit(ex => call.close(...)).forkDaemononExit adds a finalizer so that, when the stream is interrupted, we call close from the grpc-java API. This means that we need some code to be executed by grpc-java to complete our interruption.
With a single stream, this is not a problem as it can be done by another thread. But if multiple streams are interrupted at the same time, we might end up in the situation we observed where all threads from the fixed-size threadpool are waiting on interruption and there are no more threads to process the close, forming a deadlock.
To prevent that, I had to replace .interrupt with .interruptFork in zio-grpc. Unlike interrupt, interruptFork runs the interruption in a separate fiber and returns instantly, removing the risk of blocking threads. Note that at the time of writing, there was no new release of zio-grpc so you have to use the latest snapshot to get this fix.
After this change, our load test performed pretty well and we successfully went to production last week, with our reply streams pushing more than 100k messages per second to thousands of players.
Future improvements
When looking at the CPU usage on our application, because the business logic is pretty basic, most of the CPU time is still spent in the ZIO runtime, for processing the multiple streams, hubs, and queues that we’re using. Any improvements in that area would be interesting for our use case, and it looks like some are coming in ZIO 2.1, while others may come later. There is also a branch of ZIO with a dedicated runtime for streams, but I don’t know if and when it will become available.
You might also have noticed that I only implemented “streaming replies” and not “streaming requests”. This is totally doable, and we could use bidirectional gRPC streams under the hood. I found this less useful since you can simply call send multiple times if you have a stream of requests. In both cases, it will use an HTTP/2 connection under the hood, so the performance gain might not be that big, but it’s definitely something that could be added if needed.
I hope that sharing my experience was useful, and I’m looking forward to hearing from other Shardcake users if you try to use this new feature!