A Beginner's Guide to GraphQL in Scala

This article demonstrates how to create a simple GraphQL API using the Scala programming language, with the help of a library called Caliban. It is aimed at beginners: only a basic understanding of Scala and GraphQL is required for reading.
There are two primary approaches to building a GraphQL server: Schema-First and Code-Only. Schema-First involves initially defining the schema using the GraphQL Schema Definition Language (SDL), followed by defining resolvers (what to execute when a field is queried by the client) as code. Conversely, Code-Only refers to the approach where both the schema and resolvers are defined as code.
The library showcased in this article, Caliban, is primarily designed for the Code-Only approach, leveraging the benefits provided by the Scala programming language: safety (the strong type system ensures at compile-time that your schema and resolvers are fully aligned) and expressiveness (creating your API requires minimal boilerplate).
With Caliban, schemas and resolvers are defined separately, allowing for better separation of concerns and the option to use different resolvers for the same schema (e.g., for testing purposes). Another unique aspect of Caliban is that schemas are defined as data rather than a set of instructions or function calls. To define a schema, you only need to create Scala case classes and sealed traits, and you can reuse types that already exist in your code.
Defining Our Schema
We will build a simple API that allows us to query characters from the science fiction book and TV series The Expanse.
Here is the schema we aim to express, defined using the GraphQL SDL syntax:
enum Origin {
BELT
EARTH
MARS
}
type Character {
name: String!
nicknames: [String!]!
origin: Origin!
}
type Query {
characters(origin: Origin): [Character!]!
character(name: String!): Character
}In summary, we have a Character type, an Origin enum, and a root Query type that enables querying characters by origin or by name.
Now, let’s define our schema in Scala. As mentioned earlier, this is accomplished by creating simple data types, so let’s create Scala types that correspond to our GraphQL schema.
enum Origin {
case EARTH, MARS, BELT
}
case class Character(
name: String,
nicknames: List[String],
origin: Origin
)Notice how the Scala code closely resembles the GraphQL version. In this example, we are starting from scratch, so we need to create all those types. However, in real life, the types you want to expose probably already exist, making this step even simpler!
Keep in mind that if our GraphQL types were nullable (if their types didn’t end with !), we would have used the Option type in Scala (e.g., Option[String] in Scala for GraphQL’s nullable String).
Now let’s examine the Query type. It is slightly more complicated because we have arguments to consider. To handle arguments with Caliban, we use functions: characters is a function that takes an optional Origin (nullable in GraphQL terminology) and returns a list of Character: in Scala, Option[Origin] => List[Character].
case class Query(
characters: Option[Origin] => List[Character],
character: String => Option[Character]
)There is one issue here: how do we define the names of those arguments? In our desired schema, characters takes an argument named origin, but there is no equivalent in our Scala code. Caliban cannot generate these names automatically because there might be multiple arguments of the same type, making it confusing to determine which is which.
To address this, we need to create simple case classes that wrap our arguments, allowing us to assign names to them.
case class CharactersArgs(origin: Option[Origin])
case class CharacterArgs(name: String)
case class Query(
characters: CharactersArgs => List[Character],
character: CharacterArgs => Option[Character]
)This approach makes it clear that the argument for characters is named origin. We often add the suffix Args to these wrapper classes, but feel free to name them as you wish.
We’ve finished creating our schema using Scala, but how can we ensure it matches the expected SDL? This is where we will finally utilize Caliban.
//> using dep com.github.ghostdogpr::caliban-quick:2.5.0
import caliban.*
println(render[Query])The first line simply imports the Caliban dependency if you’re using Scala CLI. If you’re using sbt instead, you can add this dependency to your build.sbt file instead. We’re using caliban-quick because it provides everything you need to get a server up and running easily (more on this later).
We then import caliban.*, which brings in the few functions and types we will need in this article. After that, we call render[Query] to get the GraphQL SDL definition corresponding to the type Query, and we print it.
However, this code will not compile. To understand why, we first need to discuss how Caliban transforms Scala types into GraphQL types. We call this process schema derivation, and it involves generating an instance of the Schema trait for every Scala type that we use. The Schema trait defines the GraphQL type and how it will be resolved. There are three different ways it can be generated:
-
Automatic derivation tries to generate schemas automatically for all types used in the schema. This only requires a single import.
import caliban.schema.Schema.auto.* -
Semi-automatic derivation involves explicitly creating a
Schemainstance for each type used in the schema by calling a function that handles the process for us.import caliban.schema.Schema // this will create a schema for Origin given Schema[Any, Origin] = Schema.gen // this is an alternative way to create it enum Origin derives Schema.SemiAuto { case EARTH, MARS, BELT } -
Manual derivation involves explicitly creating a
Schemainstance for each type used in the schema by writing all the code ourselves. This can be combined with semi-auto derivation, allowing you to define some types manually and others automatically.
For the sake of simplicity in this example, we will use auto-derivation, but semi-auto derivation is recommended for more complex schemas as it offers better compilation speed, improved error messages when a type cannot be derived, and more predictable results overall.
Schema defines how to transform a Scala type into a GraphQL type. There is one more thing we need to define: how to parse an argument from the GraphQL input into a Scala value. This is done using the ArgBuilder trait, which can be derived automatically or semi-automatically, just like Schema. Note that you only need an ArgBuilder for types passed as arguments, not for types returned in the response.
Returning to our original code, let’s add those two imports:
import caliban.schema.ArgBuilder.auto.*
import caliban.schema.Schema.auto.*
println(render[Query])This will now compile and display the derived schema, which is exactly what we anticipated.
enum Origin {
BELT
EARTH
MARS
}
type Character {
name: String!
nicknames: [String!]!
origin: Origin!
}
type Query {
characters(origin: Origin): [Character!]!
character(name: String!): Character
}Writing Resolvers
Now that we have a schema, it’s time to define our resolvers.
First, let’s create some sample data to handle queries to our API. To make this example easy to run, the data will be hardcoded and loaded in memory.
val sampleCharacters = List(
Character("James Holden", List("Jim", "Hoss"), Origin.EARTH),
Character("Naomi Nagata", Nil, Origin.BELT),
Character("Amos Burton", Nil, Origin.EARTH),
Character("Alex Kamal", Nil, Origin.MARS),
Character("Chrisjen Avasarala", Nil, Origin.EARTH),
Character("Josephus Miller", List("Joe"), Origin.BELT),
Character("Roberta Draper", List("Bobbie", "Gunny"), Origin.MARS)
)Next, let’s implement some business logic for our API’s intended functionality: one function to filter characters by origin and another function to search for a character by name.
def charactersByOrigin(origin: Option[Origin]): List[Character] =
sampleCharacters.filter(c => origin.forall(_ == c.origin))
def characterByName(name: String): Option[Character] =
sampleCharacters.find(_.name == name)With Caliban, the resolver for a given type is simply a value of that type. Therefore, we can create a resolver for Query just by creating a value of the Query type!
val queryResolver =
Query(
characters = args => charactersByOrigin(args.origin),
character = args => characterByName(args.name)
)This means that if a client requests the characters field, Caliban will call the charactersByOrigin function, passing the origin value from the arguments. If they request character, Caliban will call the characterByName function, passing the name value from the arguments.
This illustrates one of the benefits of Caliban I mentioned earlier: because schemas are types and resolvers are values of those types, it’s impossible to write a resolver that returns something different from what is defined in the schema, as it would lead to a compile error. Notice also how you’ve barely had to learn anything new up to this point: creating case classes and values are basic tasks, and the code is extremely easy to read.
There’s now a final step to transform all of this into a running API.
val api = graphQL(RootResolver(queryResolver))Caliban’s graphQL function takes a RootResolver containing the resolvers for our root query type, mutation type, and subscription type. In our example, we don’t have mutations or subscriptions, so we can omit them. The function will fail to compile if it can’t find a Schema for those types; otherwise, it will return a GraphQL object representing our entire API.
This object can be used for various purposes: you can obtain the entire schema SDL from it (api.render), you can combine it with another GraphQL object to merge APIs together (api1 |+| api2), or you can annotate it with wrappers to modify its behavior (api @@ timeout(3 seconds) @@ maxDepth(50)).
Most importantly, you can transform this API object into a running HTTP server.
import caliban.quick.*
api.unsafe.runServer(8088, "/api/graphql")Caliban itself supports all the major HTTP server and JSON libraries in Scala (through the concept of adapters), but for a quick start, the caliban.quick module offers helpers to set up a running server with minimal boilerplate. We’ve chosen the adapter with the best performance for this module, so you can even keep using it until production!
Let’s now take our favourite GraphQL IDE and run a simple query targeting http://localhost:8088/api/graphql.
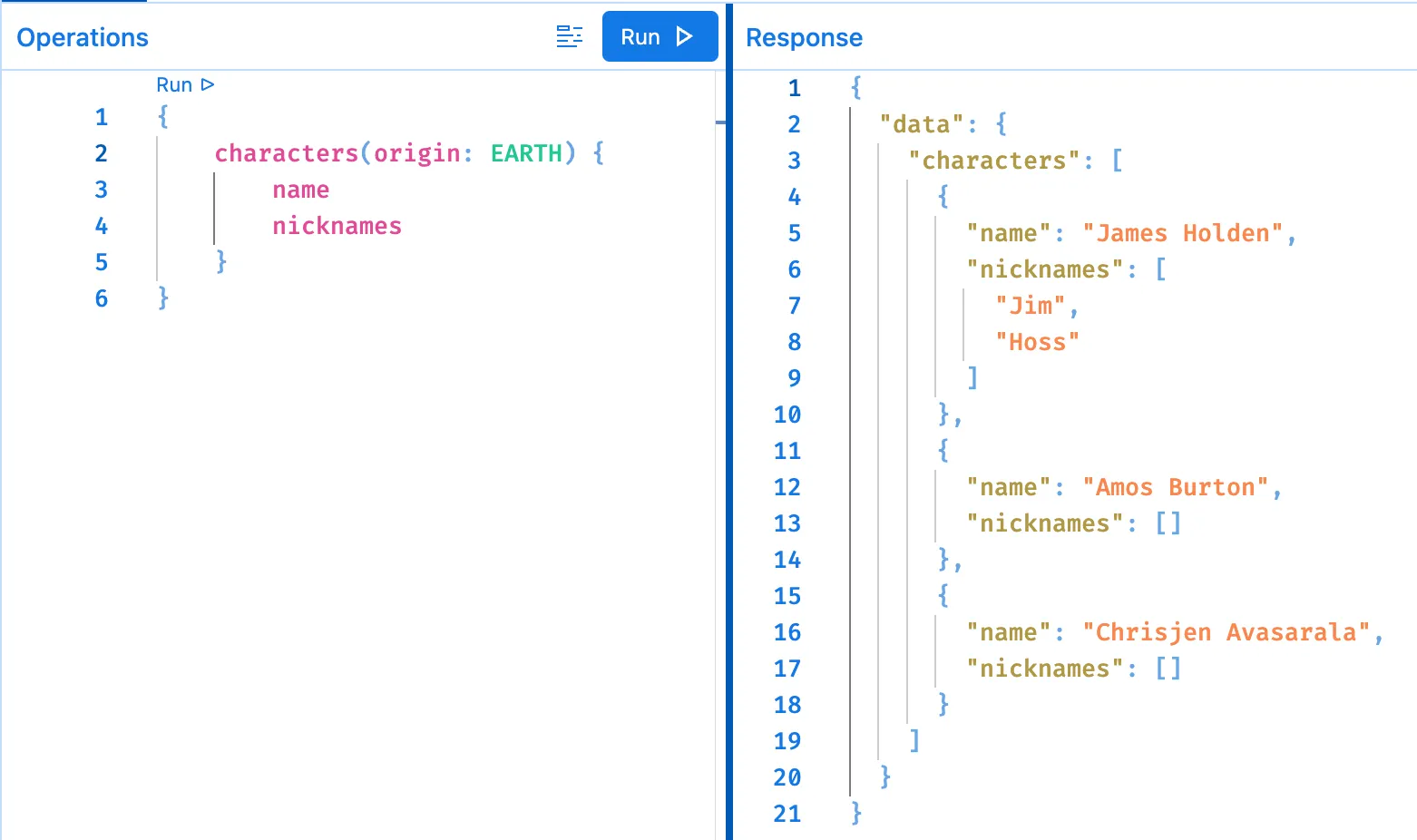
It works! We can query our data as expected.
The entire script for this example is available in this gist. To run it, simply copy it to a new folder (make sure to keep the .sc extension as it is a Scala worksheet) and then execute scala-cli run . (you will need to have Scala CLI installed).
Going Further
Of course, the example in this article was quite simple and far from what a real production API would look like. You may have many questions, such as:
-
How do I create schemas for unsupported types?
-
How can I customize the generated schemas?
-
What if my logic returns a
Future/IO/Task/etc? -
How do I optimize query execution?
-
How do I add mutations or subscriptions?
-
How should I handle authentication and authorization?
-
How can I gather metrics or traces?
Many answers to these questions (and more) can be found in the Caliban documentation, but I plan to cover these advanced topics in future articles, so stay tuned for more!