The Tri-Z Architecture: a Pattern for Layering ZIO Applications in Scala

After working on several different services and spending a lot of time improving the code to make it easier to use, I discovered a pattern for layering my applications that I found very useful.
First, a disclaimer: this architecture is not a one-size-fits-all solution. Different applications have completely different needs, which might make some layers unnecessary. Take it with a grain of salt and adapt it as you see fit!
Introduction
My main job is writing game servers, and these typically have the following characteristics:
-
Heavy business logic: game rules are complex, and each player action requires validations (to prevent illegal actions) as well as calculations (to determine the outcome).
-
High concurrency: in multi-player games, different players may perform actions at the same time, and those actions may impact each other.
-
High performance: we need to support a large number of players and respond to player actions with the smallest latency possible. This also means that we try to keep the state loaded in memory rather than reading/writing it for each request.
To handle these with ease, I organized my code into these three layers:
-
The inner core only contains pure business logic (using the
ZPuredata type). -
The middle layer consists of atomic state operations (using the
ZSTMdata type). -
The outer layer is where we run side effects (using the
ZIOdata type).
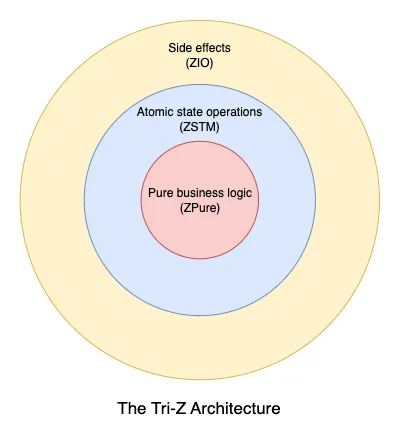
Let’s look into each of these layers in detail.
Pure business logic with ZPure
This is a topic I’ve talked about before, so I invite you to check my presentation at Scala Matsuri 2022 (slides) if you haven’t seen it.
Keeping your core business logic pure (deterministic and free of side effects) gives you a few important benefits:
-
You can test individual functions easily because they don’t require a lot of setup such as a database or even mocks for other services. You just need to provide an input and check the resulting output.
-
If you need to fail in the middle of your business logic, using pure code will ensure that there is absolutely no impact from the code that was executed before the failure happened.
-
Pure application logic can be executed multiple times, which means it can be replayed (useful for event sourcing) and retried (useful for
ZSTMas we will see later).
ZPure is a data type provided by the zio-prelude library, a sort of Either on steroids. In addition to returning an error or a result like Either[+E, +A], a ZPure[+W, -S1, +S2, -R, +E, +A] lets you do several things:
-
Access a read-only “environment” of type
R(for Reader). Typically, this is used to store configuration values that you provide only once when you run the program. -
Access an input state
S1, modify it, and potentially change its type into an output stateS2. I have not found a use case where I needed different types forS1andS2, so those two are usually the same type for me. -
Accumulate a log of values of type
W(for Writer). This is very flexible and allows for some creative usage. I’ve used it for storing events in an event sourcing application, for feeding a stream of messages to players in a game, but also for storing actual logs (that are printed in the outermost layer, since it is a side effect). There is an operator namedclearLogOnErrorto determine whether the log is reset or kept when the program fails.
To run a ZPure, you need to provide values for R and S1, and in response, you get a Chunk[W], and either an error E or an updated state S2 with a result A. It is logically equivalent to (R, S1) => (Chunk[W], Either[E, (S2, A)]), but stack-safe and with a ton of useful operators.
If you are familiar with ZIO, ZPure will feel very natural, with the main differences being that you can’t run arbitrary side effects (no attempt) or spawn fibers (no fork).
Type inference is sometimes a bit painful when working with ZPure: for example, when you use ZPure.succeed, you often need to specify explicitly what the state type S is because it cannot be inferred by the value itself. For this reason, I defined a custom trait that exposes functions that are more convenient to use, and I extend it in all of my projects.
import zio.Tag
import zio.prelude.*
import zio.prelude.fx.ZPure
trait ZPureConstructors[W, S, R: Tag, E] {
type Program[+A] = ZPure[W, S, S, R, E, A]
val unit: Program[Unit] = ZPure.unit
def pure[A](a: A): Program[A] = ZPure.succeed(a)
def fail(e: E): Program[Nothing] = ZPure.fail(e)
def inquire[A](f: R => A): Program[A] = ZPure.serviceWith[R](f)
val get: Program[S] = ZPure.get
def set(s: S): Program[Unit] = ZPure.set(s)
def inspect[A](f: S => A): Program[A] = ZPure.modify(s => (f(s), s))
def update[A](f: S => S): Program[Unit] = ZPure.update(f)
def modify[A](f: S => (A, S)): Program[A] = ZPure.modify(f)
def log(w: W): Program[Unit] = ZPure.log(w)
def when(condition: Boolean)(program: Program[Unit]): Program[Unit] =
ZPure.when(condition)(program).unit
// we have a few more helpers
}Using this little DSL makes things simpler as you don’t need to specify any type parameters since you don’t use ZPure constructors directly, and you can have all your functions return a concise Program[A] thanks to the type alias.
Here’s a little example of business logic using this DSL:
def join(userId: UserId): Program[Unit] =
for {
max <- inquire(_.maxPlayers)
size <- inspect(_.players.length)
_ <- when(currentPlayers >= maxPlayers)(fail(Error.FullGame))
_ <- update(_.playerJoined(userId))
_ <- log(PlayerJoined(userId))
} yield ()In that example, we first access the environment to get the maximum number of players allowed by the configuration, then we check the current state and fail if the game is already full. If not, we proceed to update the state and publish an event that will be sent to all users.
Code like this is ideal for writing business logic: it is pretty self-explanatory, doesn’t need to care about concurrency, and can be easily tested by running the program with different values for the state and the environment. The important idea is that this part of the code should be entirely focused on the business domain and free of all technical considerations.
An important note to conclude: as my friend Jules Ivanic often likes to say (see The Cost of your ZIO Addiction), don’t use an effect when you don’t need one! Use ZPure only when you actually need the state, the log, or the environment. If a function can only return a value or nothing, use Option. If a function returns a value or fails with an error, use Either. It will be even easier to test, and you can use ZPure.fromOption or ZPure.fromEither to integrate them into the rest of your code.
Atomic State Operations with ZSTM
One characteristic of ZPure is that there is no concept of fiber or parallelism. Running a single ZPure will only consider the provided state and there is no way that state can be modified by an external source. That means we need to deal with how concurrent requests affect the state at the calling site. Let’s look at an example.
Let’s say we develop a game. As Scala FP developers using ZIO, we typically store the game state in a Ref.
case class GameState(...)
class GameLogic(state: Ref[GameState]) { ... }When a user sends a request, we can use one of the Ref atomic operations such as update or modify to change the value of the state.
def handleRequest(request: PlayerRequest): UIO[Unit] =
state.modify { oldState =>
// we run our ZPure program
program(request).runAll(oldState) match {
// success, update the state
case (_, Right((newState, _))) => (Right(()), newState)
// error, keep the old state
case (_, Left(cause)) => (Left(cause.first), oldState)
}
}.flatMap(ZIO.fromEither)This function will run our ZPure program, which returns either a failure or a result (ignored for the sake of the example) and a new state. In the latter case, we replace the state in the Ref with this new value. Ref is designed so that if there are two concurrent requests happening at the same time, only one of them is allowed to modify the state. It uses AtomicReference under the hood, with a while loop that keeps retrying if the state has been changed between trials. Thankfully, we are using ZPure, so retrying will have no impact on the system apart from performance.
What if our program takes a little bit longer to run and we have a lot of requests? We might have contention issues with multiple fibers running the same code again and again, and only one of them succeeding each time. It feels inefficient to retry our whole business logic every time.
One solution is to switch from Ref to Ref.Synchronized. Unlike Ref, Ref.Synchronized is not optimistic and adds a Semaphore of size one to prevent concurrent execution of code accessing the same reference. Another option is to use a Queue with a single fiber processing requests. A queue is particularly well-suited for asynchronous workloads (e.g., gRPC streams), but can also be used for request-response workloads (with Promise).
Let’s say only a given list of players is allowed to join that game, and once a player leaves, they are not able to join again. This raises the question of where to store this data.
One approach is to put everything into GameState.
case class GameState(
...
allowedPlayers: Set[UserId],
leftPlayers: Set[UserId]
)One problem with putting everything in the same object is that it tends to become too large, and modifying it will involve many copy operations (for example, we need to do state.copy(leftPlayers = state.leftPlayers + userId) to add a user to leftPlayers), which is not the best UX. You can write helper functions to hide the copy, but it’s more boilerplate. Another issue with Ref.Synchronized specifically is that regardless of which part of the state you modify, you still need to wait on the same Semaphore.
The other approach is to split the state into different Ref.
class GameLogic(
state: Ref[GameState],
allowedPlayers: Ref[Set[UserId]],
leftPlayers: Ref[Set[UserId]]
)The problem here is that while each Ref offers atomic operations, there is no atomic operation between multiple Ref.
def join(userId: UserId): Task[Unit] =
for {
isAllowed <- allowedPlayers.get.map(_.contains(userId))
alreadyLeft <- leftPlayers.get.map(_.contains(userId))
_ <- ZIO.when(isAllowed && !alreadyLeft)(join(userId))
} yield ()Do you see the problem with the code above? alreadyLeft might be false, but before the join line is executed, another fiber might have added the user to leftPlayers. Yet, we’re going to proceed with join anyway!
We could introduce a Semaphore around that code, but that adds even more contention than there was already, and it feels too low-level in our code. Fortunately, there is a better option included in the ZIO library: ZSTM.
class GameLogic(
state: TRef[GameState],
allowedPlayers: TSet[UserId],
leftPlayers: TSet[UserId]
)TRef has exactly the same operators as Ref, with the only difference being that they return ZSTM instead of ZIO. What does this change? ZSTM computations can be combined together and committed all at once in a single transaction. If two transactions happen at the same time and conflict with each other, one will succeed and the other will be retried, which is why you can’t run side effects in ZSTM. Similarly, if a transaction fails, nothing will be committed and the data will remain unchanged.
Even better: structures like TSet, TMap, or TArray are specialized versions of TRef that offer convenient operators that also return ZSTM but will cause transactions to conflict only if they are accessing the same elements. This means that if a ZSTM is adding a particular key while another one is modifying another key in the same data structure, both transactions can be committed without retry, which reduces contention issues significantly.
To illustrate this, let’s revisit our previous example.
def join(userId: UserId): Task[Unit] =
ZSTM.atomically {
for {
isAllowed <- allowedPlayers.contains(userId)
alreadyLeft <- leftPlayers.contains(userId)
_ <- ZSTM.when(isAllowed && !alreadyLeft)(join(userId))
} yield ()
}First, our code became simpler because TSet has a contains method. Then, we notice the code is wrapped inside ZSTM.atomically, which can also be expressed by calling commit on the same block and turns our ZSTM into a ZIO by running the transaction. This ensures that if the same userId in allowedPlayers or leftPlayers is modified by another fiber, the transaction will be retried. It is therefore impossible to have the earlier problem where join is called while the player is in leftPlayers.
In summary, ZSTM allows us to simplify our code by avoiding the usage of copy on a large state stored in a single Ref, but also makes concurrency simpler to deal with by giving us transactions across multiple objects. Because ZSTM effects cannot have side effects (due to the fact they can be retried), they are an ideal fit for wrapping ZPure computations.
A final note on performance: while benchmarking one of my projects, I found that the current implementation of ZSTM was not as fast as expected and opened this issue. Thankfully, a large bounty was recently allocated to it and a maintainer is working on it so we can expect improvements soon! Regardless of this benchmark, I kept using it in my code because it didn’t affect the overall performance in a significant way.
Side effects with ZIO
Running a ZSTM transaction returns a ZIO: we’re now in the outermost layer! Here, we’re allowed to run side effects. Ideally, the business logic in this part of the code should be reduced to a minimum, and we should be doing side effects only.
Examples of these side effects are:
-
We might need to call some external services or APIs to get some data needed to call the business logic. Or we might need to do something after that logic is executed, for example, persisting the new state to a database.
-
We might take advantage of the log from
ZPureto forward responses to clients using aHubor publish events to aQueuethat will trigger additional processing.
You might have recognized the distinction between orchestration and choreography. In practice, both flows are useful and can be combined depending on the use case.
There is not a lot to say about this layer, as I imagine most readers are familiar with ZIO. The most important point about side effects here is where we decide not to run them. By pushing them outside of the business logic, we can separate concerns and reason about our code without conflating unrelated things:
-
The ZPure layer is where we focus 100% on our business logic.
-
The ZSTM layer is where we manage our state and its boundaries.
-
The ZIO layer is where we put everything together.
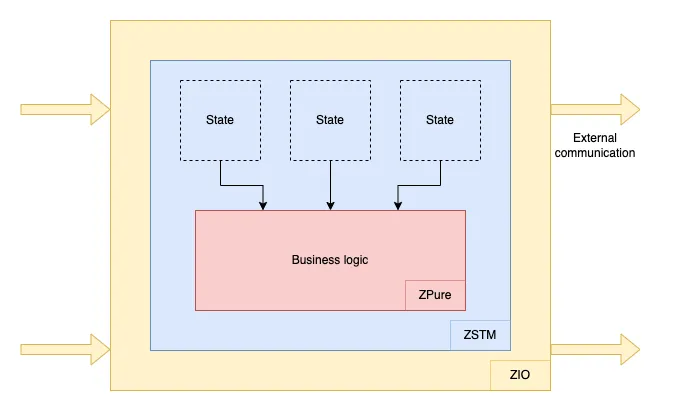
One question you might have in the context of a game server is how to scale to multiple servers when the state is stored in memory like this. Indeed, by definition, ZSTM transactions are in-memory transactions and cannot run across multiple servers. The answer is simple: players are usually grouped into smaller entities, and each entity (e.g., a single game instance or a room) runs in a single place on the cluster. To manage this, we either use distributed actors with location transparency (with Shardcake) or dedicated servers spawned on-demand (with Agones).
Conclusion
Since I “discovered” this pattern, I have started to apply it to different projects and found that it fits remarkably well with the kind of concurrent and stateful workloads I am working with, which are very typical in the game industry. I am planning to refactor a few existing projects to use this pattern, which means essentially splitting existing code into parts with clearer boundaries and concerns. This approach has significantly improved code maintainability and performance.
Is anyone out there doing something similar? I’d be curious to hear about similar code architecture patterns and practices.