Introducing PureLogic: direct-style, pure domain logic for Scala

I just released PureLogic, a new open source Scala microlibrary for writing pure domain logic using direct style. In this post, I’ll explain the motivation behind it and show how it works.
Why separate domain logic from side effects?
A well-known software architecture principle (sometimes called Functional Core, Imperative Shell) is to separate pure domain logic from side effects. Your core domain rules (validation, calculations, state transitions) should be pure functions that take inputs and return outputs, without performing I/O, accessing databases, or calling external services. Side effects are pushed to the boundaries of your application (see my post about The Tri-Z Architecture).
This separation has real benefits. Pure functions are trivial to test: no mocks, no test containers, just input and output. They’re easy to reason about because there are no hidden interactions with the outside world. And they’re reusable across different contexts: the same validation logic works whether it’s called from an HTTP handler, a CLI tool, or a batch job.
Of course, not every application fits this model perfectly. If your domain logic is inherently interleaved with I/O (a proxy, a streaming pipeline), there is less to gain. But for applications with rich domain rules (financial systems, games, e-commerce), this separation pays off quickly.
For those interested, I covered this topic in a couple talks I did at Scala Matsuri 2022 (“Beautiful Domain Logic”) and Lambda Days 2025 (“Anatomy of a Scala Game Server”).
The problem with monads
When writing this pure core in Scala, you often need a few common patterns:
- Reading configuration or environment
- Accumulating events or logs
- Managing state
- Handling errors
The traditional functional approach in Scala uses monads like ReaderWriterStateT or ZPure, or typeclasses like cats-mtl to handle these patterns. This works, but it comes with trade-offs.
Every effectful operation must be sequenced using flatMap or for-comprehensions. You can’t just use foreach to iterate over a list and perform an effect: you need traverse. The compiler often needs explicit type annotations to resolve monad transformer stacks. And new team members need to learn a whole ecosystem of abstractions before they can contribute. One reason I like ZPure is that it reduces friction a little more than other options, but still all your code needs to be inside for-comprehensions or flatMap chains.
There’s also a performance cost. Monadic code wraps every operation in a data structure and chains them via flatMap, which means heap allocations at every step. Stack traces become filled with flatMap and map frames, making debugging painful. Profilers show the effect runtime’s internals rather than your domain logic.
This overhead is sometimes dismissed as merely anecdotal. It might be in some cases, but I work on game servers where domain logic is complex enough that 63% of all allocations come from it. When I profiled our server, ZPure showed up as responsible for a large chunk of those allocations:
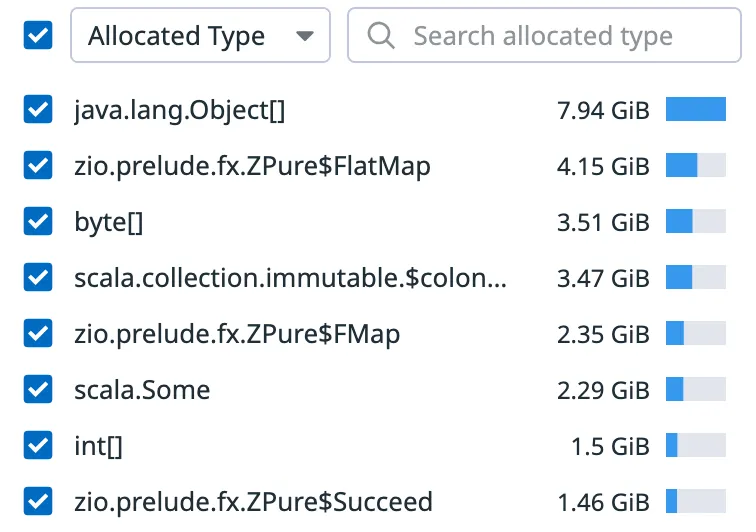
ZPure$FlatMap, ZPure$FMap and ZPure$Succeed are the monadic wrappers created when you use basic combinators like flatMap, map and succeed. In a tight domain logic loop, this adds up fast. This was one of the main motivations for building PureLogic.
A different approach
PureLogic takes a different approach. Instead of monads, it uses Scala 3’s context functions to provide 4 capabilities: Reader, Writer, State, and Abort. These are passed implicitly through given/using, so your code stays in direct style: plain Scala with regular control flow.
Here’s a quick example:
import purelogic.*
case class Account(balance: Int)
case class Config(price: Int)
def buy(quantity: Int) =
Logic.run(state = Account(50), reader = Config(10)) {
val price = read(_.price) * quantity
val balance = get(_.balance)
if (balance < price) fail("Insufficient balance")
set(Account(balance - price))
write("Purchase successful")
}
buy(2) // (Vector(Purchase successful),Right((Account(30),())))
buy(10) // (Vector(),Left(Insufficient balance))Let’s break this down:
read(_.price)accesses theConfigobject and extracts thepricefieldget(_.balance)accesses theAccountstate and extracts thebalancefail(...)short-circuits the computation with an errorset(...)updates theAccountstatewrite(...)accumulates a log entry
There are no for-comprehensions, no flatMap, no yield. Just val, if, and function calls. The capabilities are provided by Logic.run and available anywhere in the block.
Direct style vs monadic style
To see the difference more clearly, here’s the same logic written with ZPure (from ZIO Prelude) and with PureLogic:
// Monadic style (ZPure)
ZPure
.foreachDiscard(0 until n) { _ =>
for {
r <- ZPure.service[Int, Int]
s <- ZPure.get[Int]
next = s + r + 1
_ <- ZPure.set(next)
_ <- ZPure.log(next)
} yield ()
}
.flatMap(_ => ZPure.get[Int])
// Direct style (PureLogic)
(0 until n).foreach { _ =>
val next = get + read + 1
set(next)
write(next)
}
getThe direct-style version is shorter and uses standard Scala constructs. There’s no need for foreachDiscard since a regular foreach works. There’s no need for flatMap to chain the loop with a final get. It’s just code.
This simplicity compounds as your codebase grows:
- No
traverse/sequence: want to iterate over a list and perform an effect? Just useforeachormap. - Better type inference: monadic code often requires explicit type annotations, especially with monad transformers. Direct style rarely does.
- Lower learning curve: new team members don’t need to learn monad transformers or type class hierarchies. If they know Scala, they can read and write PureLogic code.
There are two trade-offs to be aware of. First, direct style means losing referential transparency: you can’t freely reorder or deduplicate expressions that use capabilities. My personal opinion is that it won’t matter much in practice for this kind of pure logic code. Second, monadic code gets trampolining for free (each flatMap returns a data structure instead of recursing), so deeply recursive monadic programs won’t overflow the stack. With direct style, you need to make recursive functions @tailrec or restructure them to avoid deep recursion.
How it works under the hood
Each capability is a trait with an implicit instance provided at the call site.
State[S] is a trait with get and set methods. When you call State(initialValue) { ... }, PureLogic creates a mutable variable scoped to that block and provides a State instance that reads and writes to it. From the outside, the function is pure: same inputs, same outputs, no observable side effects. This is the same principle as Haskell’s ST monad.
Abort[E] uses Scala 3’s boundary/break mechanism, which compiles down to a local throw/catch. This means aborting is very fast: there is no Either wrapping at each step like in monadic approaches. The Either is only constructed once, at the Abort boundary.
Reader[R] simply holds a value and makes it available implicitly. Writer[W] collects values into a buffer.
You run a program by wrapping it with the corresponding apply method:
// Individual capabilities
val result = Reader(config) { ... }
val (logs, result) = Writer { ... }
val (finalState, result) = State(initialState) { ... }
val result: Either[E, A] = Abort { ... }
// All 4 at once
val (logs, result) = Logic.run(state = initialState, reader = config) { ... }These wrappers can be nested in any order, and the nesting order determines the shape of the return type. Logic.run is a convenience that wraps all 4 in a sensible default order.
Performance
I benchmarked PureLogic against other Scala libraries that offer similar capabilities (Reader + Writer + State + Error) using JMH:
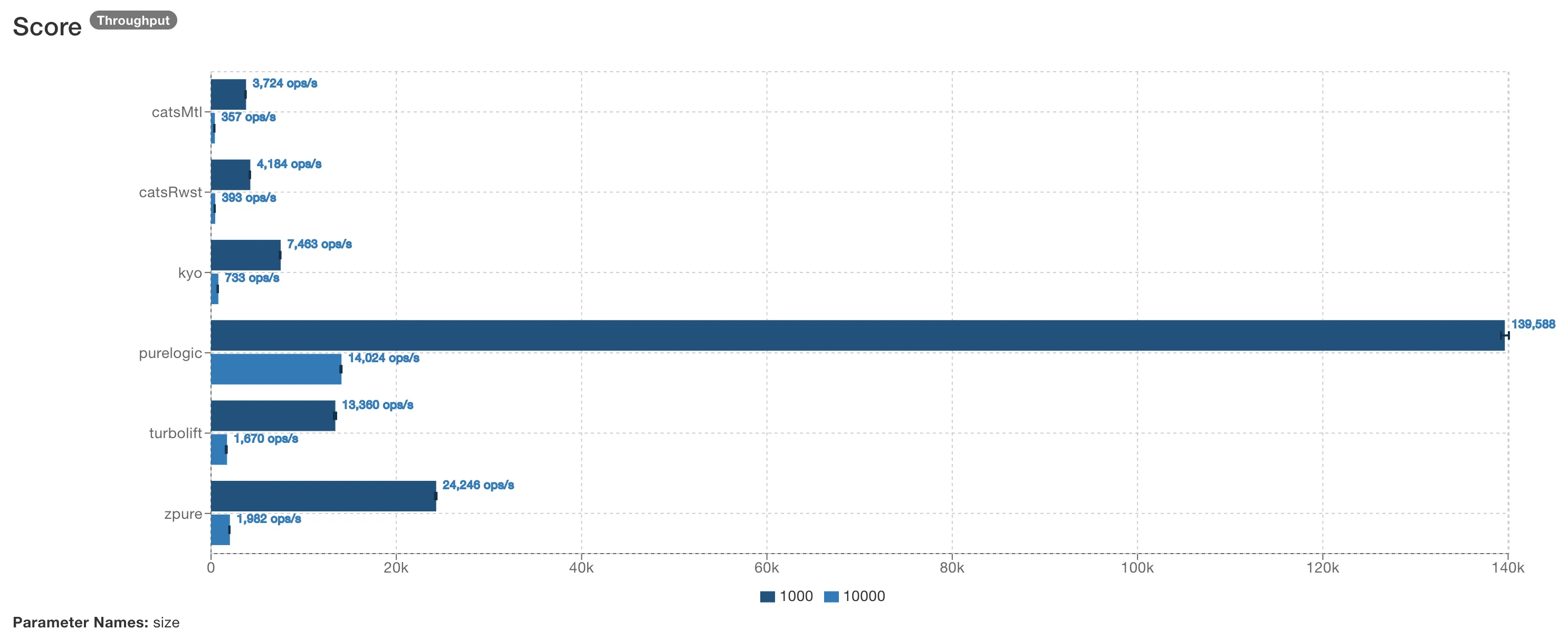
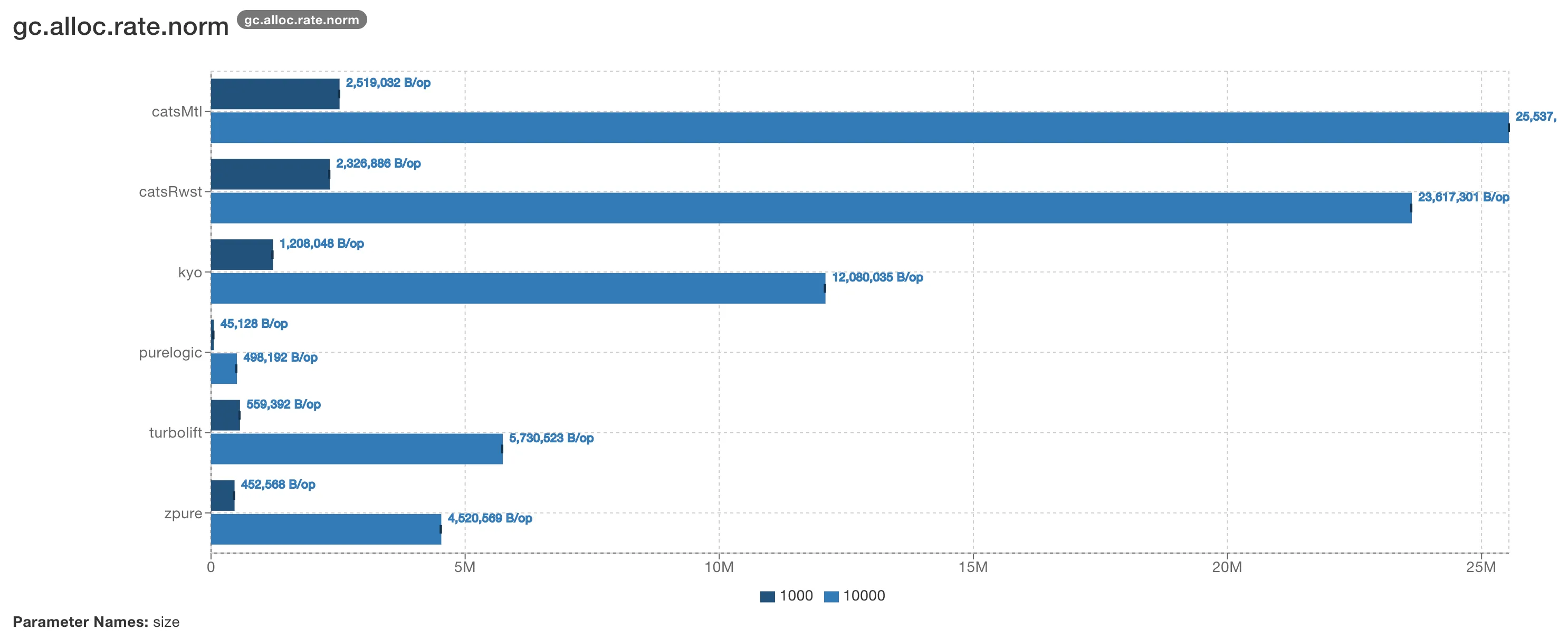
PureLogic is 7-40x faster and allocates 10-50x less memory depending on the library and workload size. This is a direct consequence of the approach: there are no monadic data structures to allocate and no flatMap chains to execute.
And because your code runs as regular Scala, you also get meaningful stack traces that point to your functions, accurate profiling that shows where time is actually spent, and straightforward debugging where you can step through your logic line by line.
Composing capabilities
Functions declare which capabilities they need via using parameters:
def validateOrder(order: Order)(using Reader[Config], State[Cart], Abort[AppError]): Unit = {
val maxItems = read(_.maxItems)
val cart = get
if (cart.items.size > maxItems) fail(AppError.TooManyItems)
// ...
}You can also use context function syntax for shorter signatures:
type MyProgram[A] = (Reader[Config], State[Cart], Abort[AppError]) ?=> A
def validateOrder(order: Order): MyProgram[Unit] = { ... }Capabilities compose naturally. If function A calls function B, and both need Reader[Config], the same instance is passed through implicitly. No need to thread parameters manually. You can also have multiple capabilities of the same kind with different type parameters (e.g. State[Account] and State[Cart]), and the compiler resolves them based on the types.
Each capability also comes with useful combinators. Reader has local (temporarily modify the reader) and focus (narrow it to a subfield). State has update, modify, localState (temporarily modify state), and focusState (operate on a subset of state). Abort has ensure, recover, and integration with Option, Either, and Try. See the documentation for the full API.
What PureLogic is (and isn’t)
PureLogic is designed for the pure core of your application, i.e. the domain logic that doesn’t do I/O. It is not a replacement for effect systems like ZIO or Cats Effect. It doesn’t manage asynchronous I/O, concurrency, or resource safety.
The intended architecture is:
- Pure core (PureLogic): domain rules, validation, state transitions, error handling
- Imperative shell (ZIO, Cats Effect, or plain Scala): HTTP handlers, database access, external services
You call Logic.run at the boundary and get back a plain value. This integrates seamlessly with any stack: there’s nothing to wire up, no interpreters to write, no runtime to configure.
Looking ahead
PureLogic’s design based on context functions and capabilities is a natural fit for Scala’s upcoming capture checking feature. Capture checking will allow the compiler to verify that capabilities don’t escape their scope (for example, ensuring that a State reference isn’t leaked outside of Logic.run). PureLogic is ready for this and it will be integrated when capture checking becomes more stable in future versions of Scala.
Getting started
PureLogic has zero dependencies, requires Scala 3.3.x LTS or later, and supports JVM, Scala.js, and Scala Native.
libraryDependencies += "com.github.ghostdogpr" %% "purelogic" % "0.1.0"Check out the documentation and the examples to get started. Feedback and contributions are welcome!